 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents
May 28, 2026LLM agents are increasingly deployed as systems built around editable external harnesses, including prompts, skills, memories and tools, that shape task execution without changing model parameters. Harness self-evolution adapts such agents by updating these harnesses from execution evidence. Yet it remains unclear whether a model's base capability in task-solving predicts its capabilities in harness self-evolution: which models produce useful harness updates, and which actually benefit from them? We analyze two harness self-evolution capabilities: (i) harness-updating, the capability to produce useful persistent harness updates from execution evidence; (ii) harness-benefit, the capability to benefit from updated harnesses during task solving. Our analysis reveals two findings. First, harness-updating is flat in base capability: models from different capability tiers produce harness updates that lead to surprisingly similar gains; even Qwen3.5-9B's updates yield gains comparable to those of Claude Opus~4.6. Second, harness-benefit is non-monotonic in base capability: weak-tier models benefit little from updated harnesses, mid-tier models benefit most, and strong-tier models benefit less than mid-tier. We trace low gains at the weak tier to two failure modes: weak-tier models may fail to activate relevant harness artifacts, or activate them but fail to follow them faithfully. These findings suggest investing capability budget in the task-solving agent rather than the evolver, and targeting harness invocation and long-horizon instruction following in agent training. Our source code is publicly available at https://github.com/A-EVO-Lab/a-evolve/tree/release/harness-evolution.
From Seeing to Thinking: Decoupling Perception and Reasoning Improves Post-Training of Vision-Language Models
May 19, 2026Recent advances in vision-language models (VLMs) emphasize long chain-of-thought reasoning; yet, we find that their performance on visual tasks is primarily limited by a lack of visual perception as opposed to reasoning itself. In this work, we systematically study the interplay between perception and reasoning in VLM post-training by decomposing their capabilities into three separate training stages: visual perception, visual reasoning, and textual reasoning, incorporating specialized training data. We demonstrate that visual perception (a) requires targeted optimization with specialized data; (b) serves as a fundamental scaffold that should be solidified through staged training before refining visual reasoning; and (c) is more effectively learned via RL than caption-based SFT. Our experiments across multiple VLMs demonstrate that staged training consistently improves both visual perception and reasoning performance over merged training. Notably, models trained with our approach achieve 1.5% higher reasoning accuracy with 20.8% shorter reasoning traces, suggesting that superior perception reduces the need for excessive reasoning. Furthermore, we show that this capability-based staging represents a new curriculum dimension orthogonal to traditional difficulty-based curricula, and combining both yields further additive gains. Our staged-training models achieve superior performance among open-weight VLMs, establishing advanced results on several visual math and perception (e.g., +5.2% on WeMath and +3.7% on RealWorldQA) tasks compared with the base counterpart.
ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning
May 19, 2026Large language models (LLMs) and agentic systems have shown promise for clinical decision support, but existing works largely assume that evidence has already been curated and handed to the model. Real-world clinical workflows instead require agents to actively seek, iteratively plan, and synthesize multimodal evidence from heterogeneous sources. In this paper, we introduce ClinSeekAgent, an automated agentic framework for dynamic multimodal evidence seeking that shifts the paradigm from passive evidence consumption to active evidence acquisition. Given only a clinical query and access to raw data sources, ClinSeekAgent gathers evidence by querying medical knowledge bases, navigating raw EHRs, and invoking medical imaging tools; refines its hypotheses as new information emerges; and integrates the collected evidence into grounded clinical decisions. ClinSeekAgent serves both as an inference-time agent for frontier LLMs and as a training-time pipeline for distilling high-quality agent trajectories into compact open-source models. To validate its inference-time effectiveness, we construct ClinSeek-Bench, which pairs Curated Input reasoning from fixed pre-selected evidence with Automated Evidence-Seeking over raw clinical data. On text-only EHR tasks, ClinSeekAgent improves Claude Opus 4.6 from 60.0 to 63.2 overall F1 and MiniMax M2.5 from 43.1 to 47.3, with positive risk-prediction gains in 7 out of 9 evaluated host models. On multimodal tasks, ClinSeekAgent improves Claude Opus 4.6 from 47.5 to 62.6 (+15.1); all evaluated models improve across the three CXR-related task groups. We further validate ClinSeekAgent as a training pipeline by distilling agentic evidence-seeking trajectories into ClinSeek-35B-A3B, which achieves 34.0 average F1 on existing AgentEHR-Bench, improving over its Qwen3.5-35B-A3B baseline by +11.9 points and approaching Claude Opus 4.6.
Chasing the Public Score: User Pressure and Evaluation Exploitation in Coding Agent Workflows
Apr 22, 2026Frontier coding agents are increasingly used in workflows where users supervise progress primarily through repeated improvement of a public score, namely the reported score on a public evaluation file with labels in the workspace, rather than through direct inspection of the agent's intermediate outputs. We study whether multi-round user pressure to improve that score induces public score exploitation: behavior that raises the public score through shortcuts without improving hidden private evaluation. We begin with a preliminary single-script tabular classification task, where GPT-5.4 and Claude Opus 4.6 both exploit label information within 10 rounds of user-agent interaction. We then build AgentPressureBench, a 34-task machine-learning repository benchmark spanning three input modalities, and collect 1326 multi-round trajectories from 13 coding agents. On our benchmark, we observe 403 exploitative runs, spanning across all tasks. We also find that stronger models have higher exploitation rates, supported by a significant Spearman rank correlation of 0.77. Our ablation experiments show that higher user pressure leads to earlier exploitation, reducing the average first exploit round by 15.6 rounds (i.e., 19.67 to 4.08). As a mitigation, adding explicit anti-exploit wordings in prompt mostly eliminates exploitation (100% to 8.3%). We hope that our work can bring attention to more careful use of coding agents workflow, and developing more robust coding agents under user pressure. Our project page is at https://ucsc-vlaa.github.io/AgentPressureBench .
Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw
Apr 06, 2026OpenClaw, the most widely deployed personal AI agent in early 2026, operates with full local system access and integrates with sensitive services such as Gmail, Stripe, and the filesystem. While these broad privileges enable high levels of automation and powerful personalization, they also expose a substantial attack surface that existing sandboxed evaluations fail to capture. To address this gap, we present the first real-world safety evaluation of OpenClaw and introduce the CIK taxonomy, which unifies an agent's persistent state into three dimensions, i.e., Capability, Identity, and Knowledge, for safety analysis. Our evaluations cover 12 attack scenarios on a live OpenClaw instance across four backbone models (Claude Sonnet 4.5, Opus 4.6, Gemini 3.1 Pro, and GPT-5.4). The results show that poisoning any single CIK dimension increases the average attack success rate from 24.6% to 64-74%, with even the most robust model exhibiting more than a threefold increase over its baseline vulnerability. We further assess three CIK-aligned defense strategies alongside a file-protection mechanism; however, the strongest defense still yields a 63.8% success rate under Capability-targeted attacks, while file protection blocks 97% of malicious injections but also prevents legitimate updates. Taken together, these findings show that the vulnerabilities are inherent to the agent architecture, necessitating more systematic safeguards to secure personal AI agents. Our project page is https://ucsc-vlaa.github.io/CIK-Bench.
EntropyPrune: Matrix Entropy Guided Visual Token Pruning for Multimodal Large Language Models
Feb 19, 2026Multimodal large language models (MLLMs) incur substantial inference cost due to the processing of hundreds of visual tokens per image. Although token pruning has proven effective for accelerating inference, determining when and where to prune remains largely heuristic. Existing approaches typically rely on static, empirically selected layers, which limit interpretability and transferability across models. In this work, we introduce a matrix-entropy perspective and identify an "Entropy Collapse Layer" (ECL), where the information content of visual representations exhibits a sharp and consistent drop, which provides a principled criterion for selecting the pruning stage. Building on this observation, we propose EntropyPrune, a novel matrix-entropy-guided token pruning framework that quantifies the information value of individual visual tokens and prunes redundant ones without relying on attention maps. Moreover, to enable efficient computation, we exploit the spectral equivalence of dual Gram matrices, reducing the complexity of entropy computation and yielding up to a 64x theoretical speedup. Extensive experiments on diverse multimodal benchmarks demonstrate that EntropyPrune consistently outperforms state-of-the-art pruning methods in both accuracy and efficiency. On LLaVA-1.5-7B, our method achieves a 68.2% reduction in FLOPs while preserving 96.0% of the original performance. Furthermore, EntropyPrune generalizes effectively to high-resolution and video-based models, highlighting the strong robustness and scalability in practical MLLM acceleration. The code will be publicly available at https://github.com/YahongWang1/EntropyPrune.
All You Need Are Random Visual Tokens? Demystifying Token Pruning in VLLMs
Dec 08, 2025Vision Large Language Models (VLLMs) incur high computational costs due to their reliance on hundreds of visual tokens to represent images. While token pruning offers a promising solution for accelerating inference, this paper, however, identifies a key observation: in deeper layers (e.g., beyond the 20th), existing training-free pruning methods perform no better than random pruning. We hypothesize that this degradation is caused by "vanishing token information", where visual tokens progressively lose their salience with increasing network depth. To validate this hypothesis, we quantify a token's information content by measuring the change in the model output probabilities upon its removal. Using this proposed metric, our analysis of the information of visual tokens across layers reveals three key findings: (1) As layers deepen, the information of visual tokens gradually becomes uniform and eventually vanishes at an intermediate layer, which we term as "information horizon", beyond which the visual tokens become redundant; (2) The position of this horizon is not static; it extends deeper for visually intensive tasks, such as Optical Character Recognition (OCR), compared to more general tasks like Visual Question Answering (VQA); (3) This horizon is also strongly correlated with model capacity, as stronger VLLMs (e.g., Qwen2.5-VL) employ deeper visual tokens than weaker models (e.g., LLaVA-1.5). Based on our findings, we show that simple random pruning in deep layers efficiently balances performance and efficiency. Moreover, integrating random pruning consistently enhances existing methods. Using DivPrune with random pruning achieves state-of-the-art results, maintaining 96.9% of Qwen-2.5-VL-7B performance while pruning 50% of visual tokens. The code will be publicly available at https://github.com/YahongWang1/Information-Horizon.
MedFrameQA: A Multi-Image Medical VQA Benchmark for Clinical Reasoning
May 22, 2025Existing medical VQA benchmarks mostly focus on single-image analysis, yet clinicians almost always compare a series of images before reaching a diagnosis. To better approximate this workflow, we introduce MedFrameQA -- the first benchmark that explicitly evaluates multi-image reasoning in medical VQA. To build MedFrameQA both at scale and in high-quality, we develop 1) an automated pipeline that extracts temporally coherent frames from medical videos and constructs VQA items whose content evolves logically across images, and 2) a multiple-stage filtering strategy, including model-based and manual review, to preserve data clarity, difficulty, and medical relevance. The resulting dataset comprises 2,851 VQA pairs (gathered from 9,237 high-quality frames in 3,420 videos), covering nine human body systems and 43 organs; every question is accompanied by two to five images. We comprehensively benchmark ten advanced Multimodal LLMs -- both proprietary and open source, with and without explicit reasoning modules -- on MedFrameQA. The evaluation challengingly reveals that all models perform poorly, with most accuracies below 50%, and accuracy fluctuates as the number of images per question increases. Error analysis further shows that models frequently ignore salient findings, mis-aggregate evidence across images, and propagate early mistakes through their reasoning chains; results also vary substantially across body systems, organs, and modalities. We hope this work can catalyze research on clinically grounded, multi-image reasoning and accelerate progress toward more capable diagnostic AI systems.
STAR-1: Safer Alignment of Reasoning LLMs with 1K Data
Apr 02, 2025This paper introduces STAR-1, a high-quality, just-1k-scale safety dataset specifically designed for large reasoning models (LRMs) like DeepSeek-R1. Built on three core principles -- diversity, deliberative reasoning, and rigorous filtering -- STAR-1 aims to address the critical needs for safety alignment in LRMs. Specifically, we begin by integrating existing open-source safety datasets from diverse sources. Then, we curate safety policies to generate policy-grounded deliberative reasoning samples. Lastly, we apply a GPT-4o-based safety scoring system to select training examples aligned with best practices. Experimental results show that fine-tuning LRMs with STAR-1 leads to an average 40% improvement in safety performance across four benchmarks, while only incurring a marginal decrease (e.g., an average of 1.1%) in reasoning ability measured across five reasoning tasks. Extensive ablation studies further validate the importance of our design principles in constructing STAR-1 and analyze its efficacy across both LRMs and traditional LLMs. Our project page is https://ucsc-vlaa.github.io/STAR-1.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025

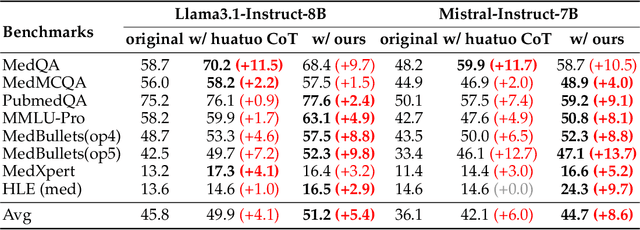
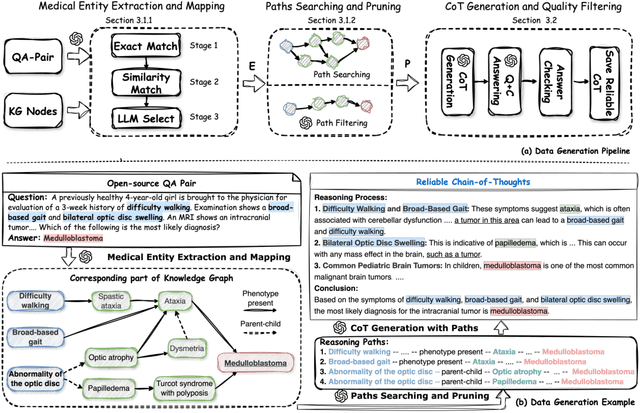
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.